
En R (CRAN) existen muchos paquetes con los que se pueden obtener excelentes gráficos de la curva ROC; sin embargo, con la finalidad de indagar un poco acerca del procedimiento para su obtención, conviene intentar hacer los cálculos y el gráfico prescindiendo de paquetes.
Es preciso disponer de las secuencias de tasas de verdaderos positivos y falsos positivos a lo largo de los umbrales impuestos por los pronósticos:
tpr = tp/(tp + fn) fpr = fp/(fp + tn) = 1 - especificidad donde: fp : falsos positivos tp: verdaderos positivos (true positive) fn: falsos negativos tn: verdaderos negativos (true negatives)
Generalmente se cuenta con una columna de pronósticos procedentes de un modelo y una columna de observaciones, como los siguientes:
set.seed(1227) obs <- rbinom(100, 1, .5) pronos <- rnorm(100, mean = obs, sd = 1)
Obs corresponde a los valores reales y 'pronos' los pronósticos provenientes de algún modelo, ficticio en este caso, pues estoy usando valores simulados.
Un primer paso será ordenar las observaciones en función de los pronósticos, estos son ordenados a su vez en modo decreciente.
# observaciones ordenadas como factor ordenado obs <- ordered(obs) levels(obs) order_pron <- order(pronos, decreasing = TRUE) obs_ord <- obs[order(pronos)] # pronosticos ordenados pronos_ord <- pronos[order_pron]El total de casos positivos y negativos se obtiene rapidamente mediante el conteo de casos positivos y negativos simplemente:
# numero de positivos n_pos <- sum(obs == "1") # numero de negativos n_neg <- sum(obs == "0")Los falsos negativos representan el número de valores falsos en cada punto del umbral (pronósticos ordenados), mediante la función cumsum se obtiene el acumulado de casos con la condición negativa.
# falsos-positivos fp <- cumsum(obs[order_pron] == "0")De modo similar se calculan los verdaderos positivos
# positivos-reales tp <- cumsum(obs[order_pron] == "1") # la curva parte de cero, añadiré un cero al inicio tp <- c(0, tp) fp <- c(0, fp)Comparando con los valores producidos por el paquete ROCR
library(ROCR) # para comprobar los cálculos library(WVPlots) # para comparar los gráficos predROCR <- predictions(pronos, obs) all.equal(predROCR@fp[[1]], fp) # [1] TRUE all.equal(predROCR@tp[[1]], tp) # [1] TRUELos valores coinciden, para el cálculo de falsos negativos 'fn' y 'verdaderos negativos 'tn' procederé de forma análoga, pero en este caso serán resultado de la sustracción de los totales. Es decir, restando el vector de falsos positivos del total de negativos y al total de positivos se le sustrayendole el vector de verdaderos positivos
tn <- n_neg - fp # verdaderos positivos fn <- n_pos - tp # falsos negativosEl siguiente cotejo muestra que coinciden:
all.equal(predROCR@fn[[1]], fn) # [1] TRUE all.equal(predROCR@tn[[1]], tn) # [1] TRUELa sensibilidad (tpr o recall) es el cociente de los verdaderos positivos entre el total de casos positivos.
sens <- tp/n_pos fpr <- fp/n_neg # igual a 1 - especificidadEl área bajo la curva (AUC) resulta de multiplicar la altura (tpr) por cada una de las diferencias entre los valores de la tasa de falsos positivos. A la manera del cálculo integral, cada diferencia representa la pequeña base de un rectangulo cuya altura es el valor correspondiente fpr, al efectuar la suma se obtiene el área.
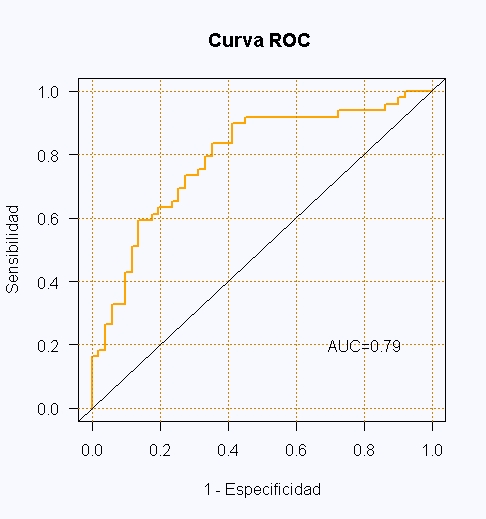
base <- diff(c(0, fp/n_neg)) areas <- sens * base auc <- sum(areas) auc # [1] 0.7895158Comprobando con ROCR:
prf <- performance(predROCR, "auc") slot(prf, "y.values") # [1] 0.7895158 all.equal(auc, unlist(slot(prf, "y.values"))) [1] TRUEDe seguidas, una posible forma de reunir estos pasos en una función:
curvaROC <- function(pronosticos, observaciones){
obs <- ordered(observaciones)
order_pron <- order(pronosticos, decreasing = TRUE)
# numero de negativos
n_neg <- sum(obs == levels(obs)[1])
# numero de positivos
n_pos <- sum(obs == levels(obs)[2])
# reales-positivos
tp <- cumsum(obs[order_pron] == levels(obs)[2])
# falsos-positivos
fp <- cumsum(obs[order_pron] == levels(obs)[1])
# ajustando la longitud de vectores tp, fp
tp <- c(0, tp)
fp <- c(0, fp)
# reales negativos
tn <- n_neg
sensit <- tp/n_pos
auc <- sum(sensit*diff(c(0, fp/n_neg)))
par(bg = "#F8F8FF")
plot(fp/n_neg, sensit,
type = "l",
col = "#FFA500",
lwd = 2,
las = 1,
ylab = "Sensibilidad",
xlab = "1 - Especificidad",
main = "Curva ROC ")
grid(NULL, col = "#CD8500")
abline(c(0, 0), c(1, 1))
text(.8, .2, labels = paste("AUC", round(auc,
digits = 3), sep = "="))
return(list(tp = tp, fp = fp))
}
li <- curvaROC(pronos, obs)
<
Por supuesto, lo conveniente y apropiado es usar las functiones contenidas en los paquetes; ya que es un código eficaz, probado y libre de bugs; una función elaborada al vuelo, puede servir bien de modo interactivo durante una sesión, pero seguramente no será robusta. No obstante, para tener la noción del cálculo subyacente, conviene hacer el ejercicio.Finalmente, el gráfico producido con el paquete WVPlots
ROCPlot(d, xvar = "pronos", truthVar = "obs",
truthTarget = 1,
title = "ROC")

Comentarios
Publicar un comentario