
Generalmente, se admite como un esquema rutinario del trabajo estadístico al momento de indagar sobre algún aspecto atinente a una población, asumir un modelo probabilístico, cuyos parámetros, siendo desconocidos, deben estimarse mediante la obtención de datos y posterior cálculo de los valores que mejor representen la data previamente recolectada. En ese último punto se halla frecuentemente implicada la optimización.
La estimación por Máximo Verosimil, es generalmente obtenida mediante la aplicación de optimizadores no lineales, que son algoritmos que, por lo general, minimizan la función que se les pasa como argumento, debido a esto, para maximizar la función de verosimilitud, se utiliza el logaritmo negativo.
En R, a mi entender, existen dos métodos, en el paquete base (hay paquetes especializados) que serían los más usados para maximizar la función de verosimiltud. Veamos un ejemplo:
tic <- data.frame(hora = sprintf("%02.f", 1:24),
reqs = c(2561, 2445, 2494, 2632, 2593, 2679, 2816, 2713,
2520, 2418, 2487, 2695, 2640, 2492, 2610, 2620,
2546, 2567, 2490, 2571, 2562, 2519, 2600, 2534))
Los datos corresponden a ventas de tickets por hora para un evento, y se supone que siguen una distribución probabilística Poisson. Si alguién deseara estimar el parámetro lambda mediante Máximo Verosimil, podría usar la función stats::optimize o stats::optim.
library(lattice)
library(latticeExtra)
# para visualizar los datos
histogram(~ reqs, data = tic,
main = "Requerimientos por Hora",
col = "#2c3e50",
ylab = "Porcentaje",
xlab = "Requerimientos",
border = "white",
alpha = .8)

Como función de verosimilitud, lo más comodo es usar -sum(dpois(y, lambda, log = TRUE)) que da el mismo resultado que usar sum(y) * log(lambda) -n * lambda que sería la que se maximizaría en la versión analítica.
# logaritmo de función de verosimilitud
loglik_pois <- function(y){
function(lambda){
- sum(dpois(y, lambda, log = TRUE))
}
}
neg_log_veros <- loglik_pois(tic$reqs)
optimize(neg_log_veros, c(2400, 3000))$minimum # se le dá un intervalo lo suficientemente amplio
# [1] 2575.167
Utilizando optim
lik_pois01 <- function(mu, y){
n <- length(y)
# con la función resultante de la derivada
# de la función de verosimilitud
log1 <- sum(y) * log(mu) - n * mu
return(-log1)
}
optim(2600, lik_pois01, y = tic$reqs, method = "Brent",
, lower = 2300, upper = 3000)$par
# 2575.167
El método Nelder-Mead que usa optim por defecto no es confiable en casos de optimización unidimensional, recomiendan 'Brent' que es equivalente al uso de optimize. Sin embargo, optimize esta restringido a un solo parámetro, optim, en cambio, permite múltiples. Se dirá que el ejemplo anterior es trivial, pues bastaba con obtener la media muestral, en efecto, es simplemente un modo de ilustrar el uso de estos optimizadores.
mean(tic$reqs) # media aritmética # [1] 2575.167Veamos el caso de una función, que luce un poco abstracta, llamada Himmelblau, es multi-modal y muy usada para someter a pruebas de performance a los algoritmos de optimización
f <- function(x1,y1) (x1^2 + y1 - 11)^2 + (x1 + y1^2 - 7)^2
x <- seq(-4.5,4.5,by=.2)
y <- seq(-4.5,4.5,by=.2)
X <- as.matrix(expand.grid(x, y))
colnames(X) <- c("x", "y")
df <- data.frame(X)
df[["z"]] <- (df$x^2 + df$y - 11)^2 + (df$x + df$y^2 - 7)^2
Para visualizar los posibles mímimos de esa función.
g1<- wireframe(z ~ x + y,
data = df,
main = "Himmelblau",
shade = TRUE,
perspective = TRUE,
scales = list(arrows = FALSE),
screen = list(z = 60, x = -120)) # 40 -60;
g2 <- wireframe(z ~ x + y,
data = df,
main = "Himmelblau",
shade = TRUE,
perspective = TRUE,
scales = list(arrows = FALSE),
screen = list(z = 50, x = -60))
gridExtra::grid.arrange(g2, g1, ncol = 2)

La gráfica pretende mostrar que los mínimos parecen estar alredor de los puntos: (-4, -4), (2, -2), (2, 2) y (-4, 4). Usando el optimizador para comprobar estos cuatro mínimos:
mins <- cbind(x = c(-4, 2, 2, -4), y = c(-4, -2, 2, 4))
f <- function(x) (x[1]^2 + x[2]- 11)^2 + (x[1] + x[2]^2 - 7)^2
# Para hallar los mínimos en estos puntos
Map(function(i, j) optim(c(mins[, 1][i], mins[, 2][j]), f)$par,
1:4, 1:4) %>% do.call(rbind, .)
# Resultando
# [,1] [,2]
# [1,] -3.779347 -3.283172
# [2,] 3.584370 -1.848105
# [3,] 3.000014 2.000032
# [4,] -2.805129 3.131435
Los resultados del optimizador pueden comprobarse al ser evaluados en la función.
Recordé estos datos, obtenidos a partir de una simulación sobre el esparcimiento de un rumor, de un estudio, que leí en internet, sobre la difusion de rumores, que data de algunos años.
rum <- data.frame(dias = 1:17,
n = c(1, 2, 4, 8, 16, 32,
64, 127, 251, 490,
926, 1676, 2790, 4022,
4809,4994, 5000))
g1 <- xyplot(n ~ dias, data = rum, grid = TRUE,
pch = 19,
main = "Difusión de un\nRumor",
ylab = "N°de Personas",
cex = 1.2,
col = "#000000")
g1
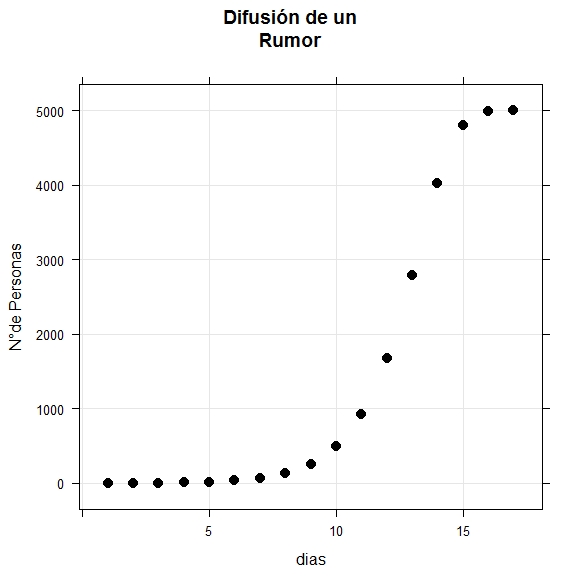
Visualmente, lucen compatibles con una función logistica Decidí usar optim, para estimar sus parámetros, a ver como resulta. En un blog, que leí hace tiempo, usaban un método como este para datos con un comportamiento parecido.
ft <- function(argms, t){
L <- argms[1] # valor maximo
k <- argms[2]
t0 <- argms[3] # momento en q alcanza el tope
L/(1 + exp(-k * (t - t0)))
}
# L: valor máximo
# t0: valor medio del sigmoide, o momento de inflexión
# k: tasa de crecimiento logístico
El valor máximo es de obtención inmediata, el tentativo punto medio 't0' se obtiene a partir de inspección visual y la tasa de crecimiento del tanteo de varios valores posibles. Todo esto, porque la función optim exige que se introduzcan valores iniciales.
# mostrando 4 de los valores k probados
kpos <- lapply(c(2.5, 1.5, 1.1, 0.7),
function(x) ft(c(L = 5000, k = x, t0 = 12), 1:17))
# para mayor comodidad, se empacan en un data frame
fx2 <- data.frame(t = 1:17,
fit1 = kpos[[1]],
fit2 = kpos[[2]],
fit3 = kpos[[3]],
fit4 = kpos[[4]])
Cambiando la forma de almacenamiento a long para el gráfico.
tfx2 <- reshape2::melt(fx2, id = "t")
tfx2$grp <- ifelse(tfx2$variable == "fit1",
"K=2.5", ifelse(tfx2$variable == "fit2", "k=1.5",
ifelse(tfx2$variable == "fit3", "k=1.1" ,"k=0.7")))
Y luego el gráfico:
par.sets <- list(superpose.symbol=list(col=c("orange", "red",
"darkgreen",
"blue", "gold3")))
gr1 <- xyplot(value ~ t, , group = grp,
data = tfx2, grid = TRUE,
type = "l",
lwd = 2,
main = "Difusion de\nRumor",
ylab = "N°Personas", xlab = "Dias",
auto.key = list(lines = TRUE, points = FALSE,
space = "right", lwd = 2),
par.settings = par.sets)
gr1 + g1

Bueno, no es un gráfico para enorgullecerse, pero si parece mostrar que la tasa de crecimiento k = 1.1, se ajusta mejor a los datos, de modo que usaré esa. Es necesario escribir una funcion de logaritmo negativo, para el máximo verosimil
logNVeros <- function(argms, df) {
mus <- ft(argms, df$dias)
- sum(dnorm(x = df$n, mean = mus,
sd = argms[4], log = TRUE))
}
Lo usual es asumir la Normal, como distribución probabilística, ello acarrea la necesidad de estimar un parámetro extra, la desviación tipica. Establecido asi, los parámetros serán los siguientes:
argms0 <- c(L = 5000, k = 1.1, t0 = 12, sd = 1900)
ajs <- optim(par = argms0, fn = logNVeros,
df = rum,
control = list(parscale = abs(argms0)),
hessian = TRUE)$par
ajs
# L k
#5246.3794438 0.9116412
# t0 sd
# 12.7641775 74.2943096
Restaría observar en un gráfico como se comportan esos valores ajustados.
# añadiendo una variable extra con los valores ajustados
rum[["ajust"]] <- vapply(1:17,
function(x) ft(ajs, x),
numeric(1))
# determinando características para los gráficos
alt_key <- list(x = .4, y = .92, corner = c(1, 1),
text = list(c("Valores Observados",
"Valores Ajustados"),
cex = .7),
lines = list(type = c("p", "l"),
col = c("black", "blue"),
pch = 19, lwd = 2))
gf <- xyplot(ajust ~ dias, data = rum,
lwd = 2,
type = "l",
main = "Difusion de un\nRumor (ajuste)",
grid = TRUE,
key = alt_key,
ylab = "N°Personas",
xlab = "Dias",
col = "#0000FF") + as.layer(g1)

Al principio subestima bastante, luego se acerca más, en fin, es solo para exporar un poco el desempeño de estos optimizadores.
Comentarios
Publicar un comentario