
Utilizando los paquetes flexdashboard y shiny, es posible crear un tablero sin que esto demande un despliegue excesivo de líneas de código, y añadiendo elementos interactivos.
Un Modo de Hacer Tableros
Un archivo flexdashboard, es basicamente un documento rmarkdown, muy usados por su reproducibilidad y porque admiten gran diversidad en el formato de archivos; tienen una estructura básica con una forma como la siguiente:
Si se está trabajando en Rstudio, este formato se obtiene seleccionando:

Luego se escoge la opción:

Para este tablero, añadiré una línea extra ( runtime) al encabezado de esta página (llamado yaml) justo debajo de vertical_layout: fill, y cambiaré la distribución de columnas a filas; además, dado que usaré la serie BJsales (datos contenidos en R desde su instalación) usaré el nombre como titulo. Debe quedar de este modo:

Después del encabezado, inmediatamente debajo , en el espacio señalado con backticks ```{r setup, include=FALSE } es preciso colocar los datos que serán usados:

Para incorporar una columna, se usa el comando 'Column' y al lado se agrega el ancho que tendrá la columna '{.sidebar data-width=200}'. Dado que la distribución será por filas, el ancho de las columnas subsiguientes puede modificarse a 800. Con dos filas, ubicando tres gráficos en la fila superior y uno en la inferior, la distribución quedará de este modo:

Si, en estas condiciones, se pulsa el botón de la parte superior (run document) se obtiene:

Es una superficie que solo muestra los espacios, donde se incluirán los gráficos y algunos dispositivos que faciliten algún tipo de interacción con ellos. Para hacer esto último, es necesario seleccionar aquellos dispositivos (widgets) que se consideren relevantes, según el diseño del tablero que se tenga en mente. La página de shiny tiene amplia información al respecto; en este caso usé los que se muestran a continuación:

Con este último añadido, el tablero adquiere el siguiente aspecto:

Solo serán tres valueBox -- un widget que presenta una cifra como resultado de alguna operación--, en la parte superior y un histograma con un gráfico de línea, en la parte inferior.
El primer valueBox lleva el siguiente código:

La documentación recomienda que aquellos valores que puedan ser modificados o actualizados desde los dispositivos del tablero, estén contenidos en una función llamada reactive. Es decir aquellas operaciones de filtrado o extraer subconjuntos del conjunto de datos, por lo general, demandan que se use este dispositivo del paquete shiny::reactive().
Los siguientes valueBox son:


Finalmente, el gráfico inferior resultó con un código un poco más largo

Los valores de la fila superior del tablero, presentan unos iconos (mu, sigma, thumbs-up, etc); a fin de obtener los iconos con letras griegas y poder cambiar los colores de los iconos de pulgares, es necesario crear un archivo .css; el que usé en este caso tiene esta forma:

Simplemente se escribe el codígo correspondiente al icono y se guarda en una carpeta. Recomiendan llamarla www y guardarla en el mismo directorio del archivo del documento flexdashboard ; es necesario escribir en el yaml la ruta y el nombre del archivo .css, si se guarda en el mismo directorio del tablero o panel y se le da por nombre p.e. 'modif', será algo como www/modif.css. Con este procedimiento, se obtiene el tablero con estas características.
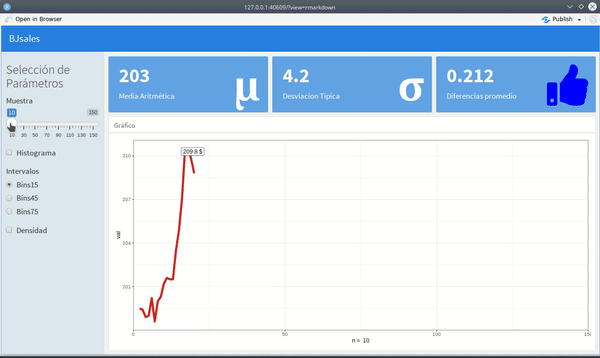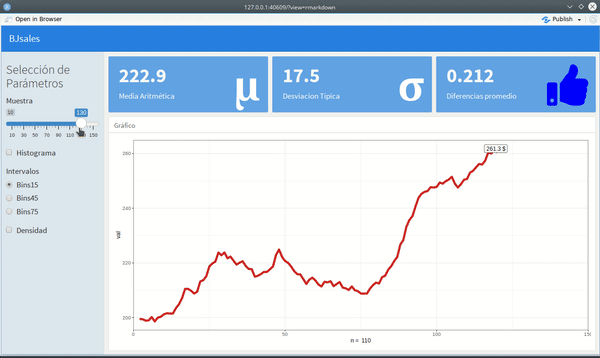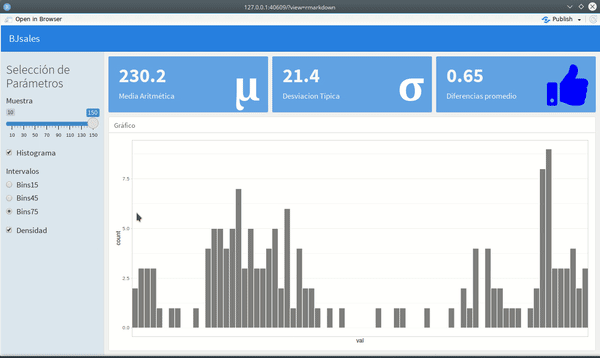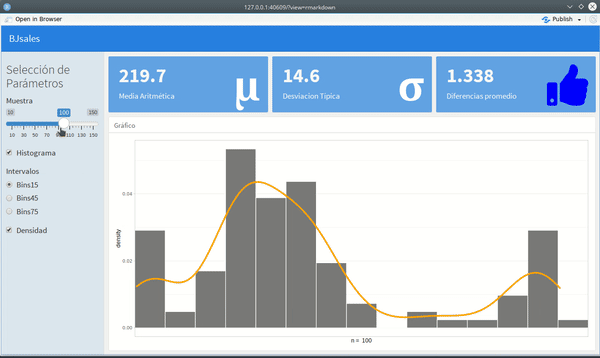

Al incorporar esto útimo, el aspecto del tablero sería como el gif que aparece al inicio.
En este caso en particular, el tablero resultante solo está pretende ilustrar, de modo muy somero (las páginas de shiny y flexdashboard son las mejores guias), algunas de las multiples capacidades contenidas en estas aplicaciones. Es decir, no está orientado a la interpretación o análisis de este conjunto de datos BJsales. .
Comentarios
Publicar un comentario