
Para hacer alguna ilustración, podemos servirnos de unos datos obtenidos de de allí seleccionamos 1 pregunta de una encuesta sobre el uso de Wikipedia en una universidad, para ver cómo se distribuyen las respuestas a través de sus distintas facultades. El código para cargar los datos:
library(ggplot2)
library(sjPlot)
q <- "~/wiki4HE.csv" # ruta local donde se guarda el archivo .csv
preg <- "¿El uso de Wikipedia facilita el desarrollo de nuevas habilidades?"
cat(readLines(q, n = 10), sep = "\n") # lectura previa
tb <- read.csv(q, sep = ";", na.strings = c("?", NA)) # las NA aparecen como '?'
Pretendemos graficar la opinión de las distintas facultades en relación con Wikipedia como un factor que facilita la adquisición de nuevas habilidades y dichas respuestas estarán a su vez divididas entre usuarios registrados y no registrados. Por ello, tomaremos estas tres variables del conjunto de datos. Originalmente aparecen contenidas en el archivo como: USERWIKI, DOMAIN, PU1.
preg <- "¿El uso de Wikipedia facilita el desarrollo de nuevas habilidades?"
tby <- na.omit(tb[, c("USERWIKI", "DOMAIN", "PU1")])
tby <- tby[!(tby$DOMAIN == 6), ] #exluido por no aparecer en la descripción
De seguidas, es conveniente producir los agreegados y porcentajes de cada respuesta.
t_ag <- data.table::setDT(tby)[, .N, by = c("USERWIKI", "DOMAIN", "PU1")]
data.table::setDT(t_ag)[, Nt := sum(N), by = c("USERWIKI", "DOMAIN")]
data.table::setDT(t_ag)[, pct := round((N / Nt) * 100, digits = 1)]
t_ag <- as.data.frame(t_ag[order(t_ag$USERWIKI, t_ag$DOMAIN, t_ag$PU1), ])
Las etiquetas, para cada una de las variables son las siguientes:
labs_fac <- c("Artes y Humanidades",
"Ciencias", "Ciencias De la Salud",
"Ingenieria y Arquitectura", "Ley & Politica") # facultad
labss <- c("Muy en Desacuerdo",
"Desacuerdo",
"Neutral",
"De acuerdo",
"Muy De acuerdo") # modalidades de respuesta
lab_wk <- c("Usuario No registrado",
"Usuario registrado") # usuario o no
Conversión de las variables en tipo 'factor' y cambio de nombre:
t_ag <- transform(t_ag, DOMAIN = factor(DOMAIN, levels = 1:5,
labels = labs_fac),
PU1 = factor(PU1,
levels = 1:5,
labels = labss),
USERWIKI = factor(USERWIKI,
levels = 0:1,
labels = lab_wk) )
colnames(t_ag) <- c("UsuarioWiki", "facultad", "respuestas", "n",
"N", "pct")
Diagrama de Barras 100%
El código para producir un gráfico que muestre los porcentajes de respuesta por facultades se muestra de seguidas.
En primer lugar creamos un tema:
th_01 <- theme(
#title = element_text(hjust = 0),
axis.title.x = element_blank(),
axis.ticks.length = unit(.25, "cm"),
panel.background = element_rect(fill = "#ffffff"),
panel.grid.major = element_line(colour = "#CBCBCB"),
legend.position = "top",
strip.background = element_rect(fill = "#545454"),
strip.text.y = element_text(face = "bold", colour = "white")
)
cols <- c("#8B1A1A", "#FF3030" , "#C1CDCD","#53868B", "#191970") # colores para las barras
El gráfico se obtiene con:
ggplot(t_ag, aes(x = facultad, y = n, fill = respuestas)) +
geom_bar(stat = 'identity', col = "#FFFFFF", position = position_fill(reverse = TRUE)) +
geom_hline(yintercept = .5, col = "#FFFFFF") +
scale_fill_manual(labels = labss, values = cols) +
scale_y_continuous(breaks = seq(0, 1, by = .1),
labels = scales::percent_format(),
position = "right", expand = c(.01, .01)) +
facet_wrap(~ UsuarioWiki, ncol = 1,
strip.position = "right") +
coord_flip() +
theme_light() + th_01 + ggtitle(preg)
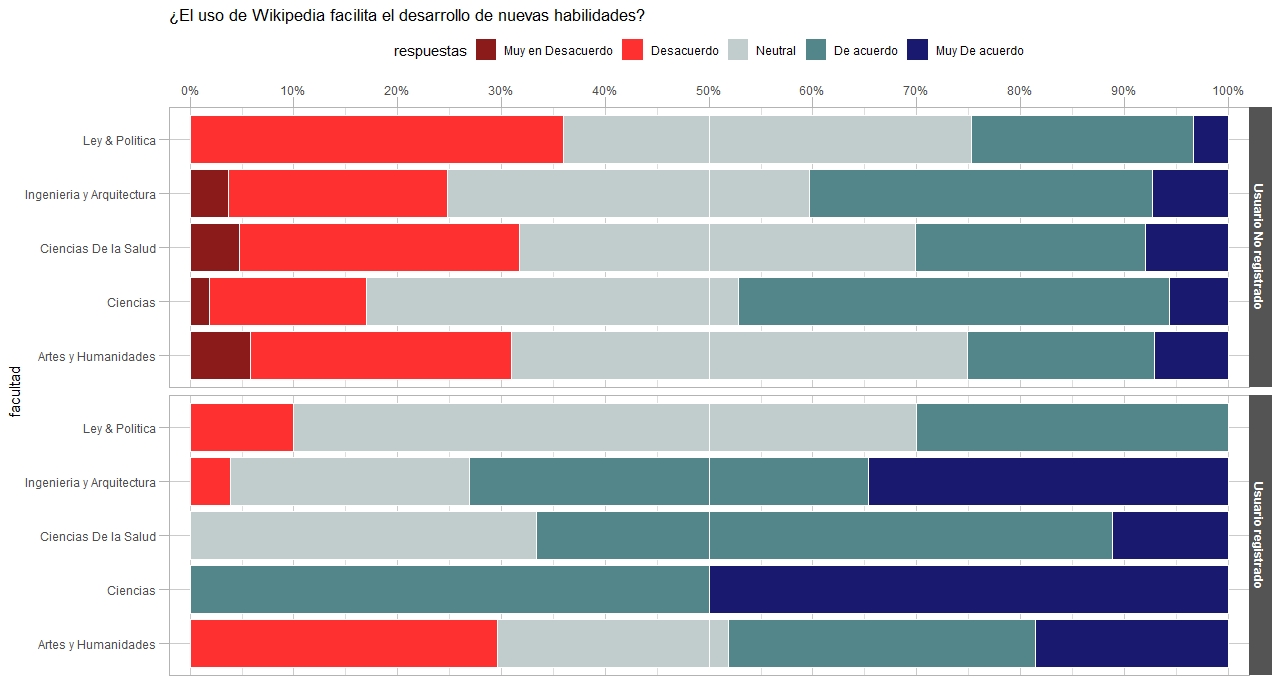
Estos gráficos suelen ofrecer la ventaja de tener una línea básica de comparación, que permite discernir haciá que opinión se inclina el 50% de la muestra o 3/4 partes de la muestra, en fin; no obstante, suele ocurrir que exista el requerimiento de que las barras presenten los porcentajes, en cuyo caso será necesario añadir una nueva columna:
t_ag <- as.data.frame(data.table::setDT(t_ag)[, pos := cumsum(pct) - .5 * pct, by = c("UsuarioWiki", "facultad")]
Con esto el código puede ejecutarse con pequeños cambios:
ggplot(t_ag, aes(x = facultad))+
geom_col(aes(y = pct, fill = respuestas), col = "#FFFFFF", position = position_stack(reverse = TRUE)) +
geom_hline(yintercept = 50, col = "#FFFFFF") +
geom_text(aes(x = facultad, y = pos, label = pct,
group = respuestas), size = 3.5, col = "#FFFFFF",
fontface = "bold") +
scale_fill_manual(labels = labss, values = cols) +
scale_y_continuous(breaks = seq(0, 100, by = 10),
position = "right", expand = c(.01, .01)) +
facet_wrap(~ UsuarioWiki, ncol = 1, strip.position = "right") +
coord_flip()+ th_01 + ggtitle(preg)
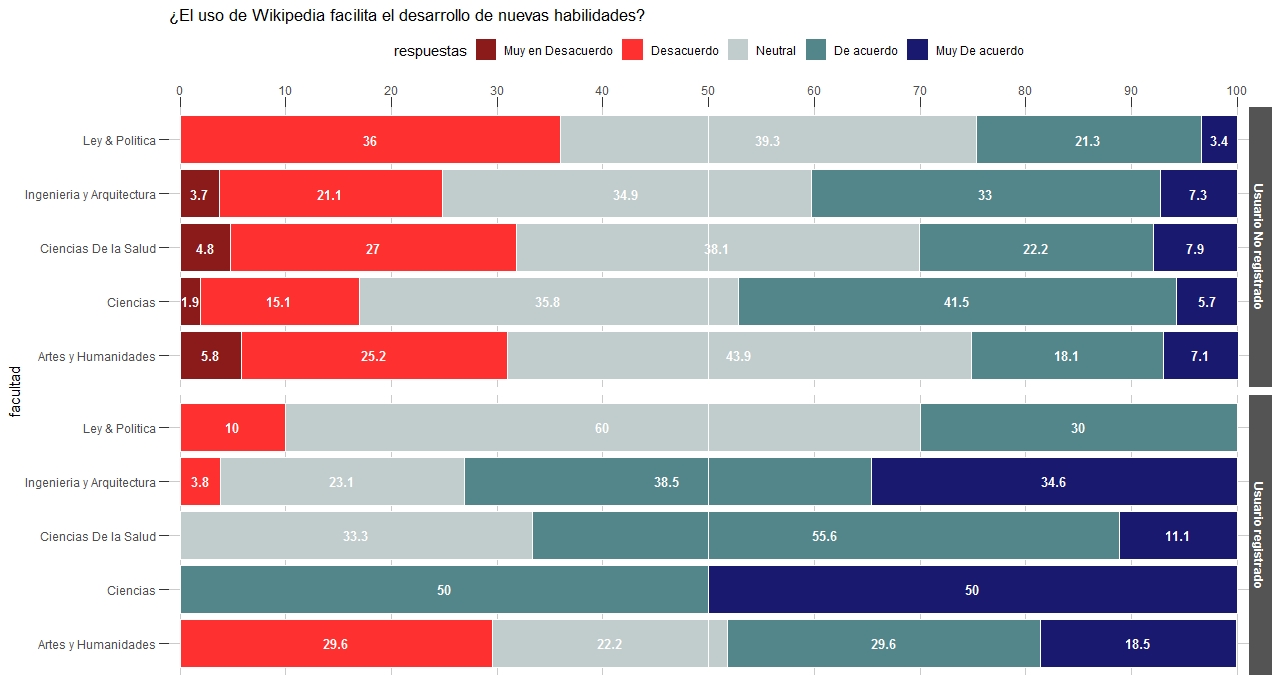
Gráfico de Barras Divergentes
Este tipo de gráificos, presenta a los participantes 'indiferentes' divididos, un 50% de los indiferentes del lado positivo y la otra mitad del negativo. ggplot2, a pesar de todas las facilidades que ofrece, no he encontrado un método directo de lograr esto, generalmente las escalas con valores negativos presentan problemas. Sin embargo 'geom_segment' ofrece una especie de artificio para obtener este tipo de gráficos, calculando las posiciones de las barras según esta condición de que los 'indiferentes' queden divididos por partes iguales, estos cálculos se pueden lograr rapidamente con un for-loop, si todas las modalidades están presentes:
compl_fac <- expand.grid(UsuarioWiki = lab_wk, facultad = labs_fac,
respuestas = labss)
dx <- merge(compl_fac, t_ag,
by = c("UsuarioWiki", "facultad", "respuestas"),
all.x = TRUE)
compl_fac <- expand.grid(UsuarioWiki = lab_wk, facultad = labs_fac,
respuestas = labss)
dx <- merge(compl_fac, t_ag,
by = c("UsuarioWiki", "facultad", "respuestas"),
all.x = TRUE)
dx[is.na(dx)] <- 0
dx <- dx[, -7]
labfac01 <- c("Ciencias", "Ingenieria y Arquitectura",
"Ciencias De la Salud", "Artes y Humanidades",
"Ley & Politica")
dx$facultad <- factor(as.character(dx$facultad),
levels = labfac01) # para que las barras aparezcan de menor a mayor
dx <- dx[order(dx$UsuarioWiki, dx$facultad, dx$respuestas),]
x <- dx$respuestas
y <- dx$pct
z <- vector("numeric", length(y))
for (i in seq(46)) {
if (i %in% which(x == "Muy en Desacuerdo")){
z[i] <- 0 - y[i] - y[i + 1] - .5 * y[i + 2]
z[i + 1] <- 0 - y[i + 1] - .5 * y[i + 2]
z[i + 2] <- 0 - .5 * y[i + 2]
z[i + 3] <- 0 + .5 * y[i + 2]
z[i + 4] <- 0 + y[i + 3] + .5 * y[i + 2]
}
}
dx$ref <- z # nueva variable
Se trata de ir calculando las posiciones de las barras, para obtener las posiciones de las etiquetas:
dx$ftext <- dx$ref + dx$pct/2 dx1 <- dx[dx$n != 0, ] # eliminando los ceros añadidos arriba por conveniencia
El código que sigue presenta un gráfico de barras divergentes:
ggplot(dx1) +
geom_segment(aes(x = facultad, y = ref, xend = facultad,
yend = pct + ref,
colour = respuestas),
size = 12) +
geom_hline(yintercept = 0, col = "#FFFFFF") +
coord_flip() +
scale_colour_manual(labels = labss, values = cols) +
scale_y_continuous(breaks = seq(-60, 100, by = 20),
limits = c(-60, 100),
expand = c(0.01, 0.01), position = "right") +
geom_text(aes(label = paste(pct, "%"), x = facultad, y = ftext),
size = 3.5, fontface = "bold", col = "#FFFFFF") +
facet_wrap(~ UsuarioWiki, ncol = 1, scales = "free",
strip.position = "right") +
th_01 + ggtitle(preg)

Este tipo de gráficos son altamente favorecidos,Robbis y Heigerger, los recomiendan. Sin embargo, existen detractores también, entre las críticas encontramos que: las barras no comparte una línea básica común, lo cual dificulta la comparación y que al dividir a los neutrales por la mitad, se está diciendo que una parte de ellos es neutral con tendencia positiva y la otra neutral pero hacia el lado negativo; y la muestra no da ninguna base para saber si eso es cierto. Otros dicen que las barras divergentes son mejores, si se excluyen a los neutrales, lo que nos llevaría al paquete sjPlot.
Con el paquete sjPlot los datos no deben estar pre-sumariados, lo cual puede ser favorable en ocasiones, pero en otras no. En todo caso, si es conveniente que los datos estén etiquetados, a la manera usual en SPSS, en R los tipo 'factor' son más frecuentes, quiza por ello existe tambien un paquete que facilita la tarea para etiquetar los datos, llamado 'sjlabelled'. La forma como estan presentados nuestros datos no es apropiada para esta funcion, por ello habrá que recomponerlos para que cada facultad quede como una variable (columna)
tbz <- tby
tbz$k <- paste(tby$USERWIKI, seq_along(tby$DOMAIN), sep = ":") #variable artificial para
# que funcione el reshape
dw <- reshape2::dcast(tbz,
formula = USERWIKI + k ~ DOMAIN,
drop = FALSE,
#fill = 0,
value.var = 'PU1')
dw <- dw[, -2] # eliminando la variable artificial
colnames(dw) <- c("UsuarioWiki", paste0("cat", 1:5)) # nuevos nombres
No encontré, en la funcion sjPlot::plot_likert, un modo de hacer 'facet' es decir de presentar el gráfico dividido en paneles (usuario no usuario), a pesar de que el objeto resultante es 'ggplot2'. De todos modos, esto se puede subsanar con una función de gridExtra. Pero primero, es necesario separar la data.
dww <- split(dw[, -1], dw$UsuarioWiki)
d1 <- dww[[1]]
d2 <- dww[[2]]
d1[] <- lapply(d1, function(x) factor(x,
levels = 1:5,
labels = labss))
d2[] <- lapply(d2, function(x) factor(x,
levels = 1:5,
labels = labss))
d1[] <- lapply(d1,
function(x) sjmisc::to_value(x, keep.labels = TRUE))
d2[] <- lapply(d2,
function(x) sjmisc::to_value(x, keep.labels = TRUE))
d1 <- set_label(d1, label = labs_fac)
d2 <- set_label(d2, label = labs_fac)
Todo este procedimiento es para asignar las etiquetas a los datos y dividirlos, para obtener gráficos separados, finalmente con se aplica la función para obtener los gráficos
g1 <- plot_likert(d1,
catcount = 4, cat.neutral = 3,
sort.frq = "neg.desc",
reverse.scale = TRUE,
show.legend = FALSE,
geom.colors = "RdBu",
reverse.colors = TRUE,
grid.range = c(1, .8)) +
labs(caption = "Usuario No Registrado") +
theme_light() +th_01 + ggtitle(preg)
g2 <- plot_likert(d2,
catcount = 4, cat.neutral = 3,
sort.frq = "neg.desc",
reverse.scale = TRUE,
#show.legend = FALSE,
geom.colors = "RdBu",
reverse.colors = TRUE,
grid.range = c(1, .8)) +
labs(caption = "Usuario Registrado") +
theme_light() +th_01 #+ ggtitle(preg)
gridExtra::grid.arrange(g1, g2, ncol = 1)

Esta función ofrece la ventaja de los datos se pasan sin agregados previos, sin embargo, esto no es siempre es ventajoso, pues hay ocasiones en las que las circunstancias exigen un procesamiento previo, antes de graficar; por otra parte, si lo datos no están dispuestos en el modo que require la función, igualmente será necesario hacer manipulaciones sobre su estructura, para obtener el resultado deseado.
El segmento de los neutrales es considerado, por lo general, de poco interés en los análisis, quiza por eso sea más apropiado que aparezcan aparte en el gráfico, además de que si facilitan la comparación entre las barras.
En cuanto a lo apropiado o no de las barras divergentes, me parece que es cuestión de opiniones, generalmente los métodos tienen pros y contras; personalmente prefiero los gráficos sobre la base de 0-100%, me parece que se leen más rápido y se establecen comparaciones con mayor facilidad.
Comentarios
Publicar un comentario