En esta ocasión me propongo ilustrar un procedimiento para identificación de clusters, a través del método kmeans, contenido en el paquete 'base' del software R; aprovechando también al eficaz paquete data.table; que tiene una sintaxis similar a la usada en los data.frames.
Los métodos de clustering, usualmente son útiles para hallar diferencias, que permitan agrupar elementos similares, según determinadas características. Mediante esas agrupaciones, se espera aumentar el conocimiento que se tiene de un área específica, desarrollar hipótesis o estrategías para abordar o tratar los elementos pertenecientes a esos conjuntos.
El proceso de identificación de grupos, se realiza en función de características de interés, que estarán contenidas en los datos que se tengan disponibles. Los rasgos diferenciales entre agrupaciones, son muchas veces tenúes y, contrario a lo que cabría esperar, en ocasiones, no existen fronteras bien demarcadas entre elementos en un espacio multivariante. En todo caso, es una posibilidad indeseable, que sin embargo, puede estar presente.
Según la índole de los datos disponibles tales serán las métricas que será posible calcular. Hace algún tiempo, leí un post, en el blog de la dra. Kimberly Coffey, sobre este mismo tema. Voy a seguir sus pasos, usando el dataset que se puede descargar, sin ningún protocolo, de la dirección:
Este conjunto de datos permite intentar un clustering, a partir de los atributos usados en el método para evaluación de clientes RFM, por sus siglas en inglés: recency, frequency y monetary. Son tres variables, a través de las cuales, se puede conocer qué tan recientes son las compras del cliente en cuestión, qué tan frecuentes, y el valor en moneda de esas adquisiones, en la tienda o negocio interesado.
Anteriormente mencioné que el procedimiento kmeans no admite NAs, los cuales son numerosos, en este dataset, y están concetrados precisamente en la variable que será pivote para el análisis. La solución rápida será prescindir de ellos.
Salta a la vista que existen algunos valores negativos en la variable 'cantidad', causados por devoluciones,estas devoluciones (valores negativos) deberían cancelarse, en su mayoría,con las ordenes previas, que luego fueron revertidas. Con un gráfico, puede hacerse una comprobación rápida. Hace falta añadir antes la variable 'ingreso'.
Al parecer los valores negativos, tienen una compensación correspondiente en los datos; de modo que al agregarlos tenderan a cancelarse unos con otros (en sus mayoria)
RFM
La variable ingreso, fue creada más arriba, al agregarla por clientes tendríamos la variable monetario; restaría calcular la frecuencia y qué tan recientes son las compras. La palabra recency, la he visto traducida como recencia, realmente no si es una traducción apropiada, sin embargo, para los efectos de este escrito, me pareció conveniente, para designar esa variable.
La fecha de facturación, aparece como tipo 'character', es preciso transformarla en tipo 'date' para poder efectuar operaciones sobre ella.
Para observar estas variables en un plot la transformación a logaritmos mejora la visualización. Los clientes representados en la parte inferior de ambos gráficos, son de poco interés para el negocio, desde el punto de vista de el ingreso resultante de sus adquisiciones. Los clientes del extremo superior izquierdo (color rojo), en el caso de las frecuencias; son los de mayor interés desde el punto de vista monetario.
Los clientes representados en la parte inferior de ambos gráficos, son de poco interés para el negocio, desde el punto de vista de el ingreso resultante de sus adquisiciones. Los clientes del extremo superior izquierdo (color rojo), en el caso de las frecuencias; son los de mayor interés desde el punto de vista monetario.
KMEANS
Reatan 40 observaciones, cuyo valor monetario es negativo (devoluciones sin contrapartida. Además hay otras 8 que en transformación logaritmica, tienen valor inferior a cero, debido a lo bajo de los montos. Decidí prescindir de esas observaciones.
Para aislar los efectos, debidos a diferencias em las magnitudes de las tres variables, conviene centrarlos en media y varianza.
La varianza intra-clusters, disminuye a medida que se incrementa el número de clusters. De hecho, seguramente habrá un punto en el que comenzará subir. Ese punto podría ser el mejor; pero en ese caso, el número de clusters dificultaría toda labor de interpretación. Lo cual dejaría el problema, practicamente en el mismo punto de partida. Es usual buscar trade off. Por ejemplo, en el cuál las disminuciones marginales en la varianza intra-clusters, comienzan a hacerse más pequeñas: el método del codo. Usando ese método, el número apropiado de clusters, estaría en torno a cinco.
El paquete factoextra, ofrece un método equivalente para encontrar el número apropiado de clusters
Los resultados son bastante parecidos.
Para observar la configuración de los clusters, en torno a una cifra resumen, por ejemplo la mediana. Un procedimiento, análogo al anterior, permite guardar en una lista las medianas, para todos los resultados,en cuanto a cantidad de clusters propuestos.
La lista do_clus, contiene agrupaciones de hasta 10 clusters. Sin embargo, aquí solo se muestran los resultados para cinco clusters (medianas) A medida que el número de clusters crece, los grupos comienzan a hacerse indiscernibles. .
El cluster 5, es el de mayor valoración monetaria, mayor frecuencia de compras y sus adquisiciones son de más reciente data; le sigue el cluster dos, sino en cuanto la datacion de sus compras, si en cuanto a la frecuencia y monto de las adquisiciones, serían las mayores, después de las correspondientes al cluster 5. Luego los clusters 1, 3 y 4 corresponden a segmentos medios sus compras tienden a ser más esporádicas y de monetariamente más bajas. El segmento 4 tiene un período de adquisiciones reciente, pero su frecuencia y valor monetario lo asemeja al cluster 3. En fin, una mirada conocedora desde el punto de vista los dueños o encargados de la tienda, podría facilitar una mejor interpretación de estos resultados. Incluso más o menos clusters podrían tener sentido, de acuerdo a la lectura que ellos hagan de resultados como estos.
Por último puede resultar apropiado, observar estos 5 clusters en 3 dimensiones. Con la ayuda de algunos paquetes se puede obtener brevemente una visualización en 3d, incluso una animación.
Los métodos de clustering, usualmente son útiles para hallar diferencias, que permitan agrupar elementos similares, según determinadas características. Mediante esas agrupaciones, se espera aumentar el conocimiento que se tiene de un área específica, desarrollar hipótesis o estrategías para abordar o tratar los elementos pertenecientes a esos conjuntos.
El proceso de identificación de grupos, se realiza en función de características de interés, que estarán contenidas en los datos que se tengan disponibles. Los rasgos diferenciales entre agrupaciones, son muchas veces tenúes y, contrario a lo que cabría esperar, en ocasiones, no existen fronteras bien demarcadas entre elementos en un espacio multivariante. En todo caso, es una posibilidad indeseable, que sin embargo, puede estar presente.
Según la índole de los datos disponibles tales serán las métricas que será posible calcular. Hace algún tiempo, leí un post, en el blog de la dra. Kimberly Coffey, sobre este mismo tema. Voy a seguir sus pasos, usando el dataset que se puede descargar, sin ningún protocolo, de la dirección:
https://archive.ics.uci.edu/ml/datasets/Online+RetailLos datos se pueden leer directamente desde R, utilizando el comando XLconnect::readWorksheet, en este caso, opté por descargarlos directamente al computador.
library(data.table) # activar el paquete data.table en R p <- "~/OnlineRetail.txt"Una vez en el cumputador, pueden ser leídos rapidamente, con el comando data.table::fread(). Pero antes se pueden leer algunas líneas de los registros, para tener una idea de comó estan estructuradas las variables.
cat(readLines(p, n = 6), sep = "\n")# un vistazo preliminar de los datos InvoiceNo StockCode Description Quantity InvoiceDate UnitPrice CustomerID Country 536365 85123A WHITE HANGING HEART T-LIGHT HOLDER 6 01/12/2010 08:26 2,55 17850 United Kingdom 536365 71053 WHITE METAL LANTERN 6 01/12/2010 08:26 3,39 17850 United KingdomUna vez cargados los datos, puede ser conveniente traducir el nombre de las variables:
f <- fread(p, dec = ",")
colnames(f) <- c("nFactura", "co_inventario",
"descripcion", "cantidad",
"fecha_factura", "precioUnitario",
"id_cliente", "pais") # para traducir los
# nombres de las variables.
vapply(f, class, character(1)) # identifica los
#tipos de variables presentes
nFactura co_inventario descripcion cantidad fecha_factura precioUnitario id_cliente pais
"character" "character" "character" "integer" "character" "numeric" "integer" "character"
Tambíén es imprescindible sondear la existencia de datos ausentes (missing), teniendo en cuenta que la técnica kmeans, es incompatible con datos ausentes.
do.call(rbind, lapply(f, function(x) sum(is.na(x))))
[,1]
nFactura 0
co_inventario 0
descripcion 0
cantidad 0
fecha_factura 0
precioUnitario 0
id_cliente 135080
pais 0
dim(f) # número de observaciones en el dataset 541909 8
Este conjunto de datos permite intentar un clustering, a partir de los atributos usados en el método para evaluación de clientes RFM, por sus siglas en inglés: recency, frequency y monetary. Son tres variables, a través de las cuales, se puede conocer qué tan recientes son las compras del cliente en cuestión, qué tan frecuentes, y el valor en moneda de esas adquisiones, en la tienda o negocio interesado.
Anteriormente mencioné que el procedimiento kmeans no admite NAs, los cuales son numerosos, en este dataset, y están concetrados precisamente en la variable que será pivote para el análisis. La solución rápida será prescindir de ellos.
f <- na.omit(f) # eliminar NAsA través del comando vapply, fue posible observar que las variables presentes son en su mayoría tipo character; identifican facturas, clientes, articulos a la venta, etc. Sin embargo, existen dos variables de tipo númerico, que es conveniente observar en un sumario, para mejorar la percepción acerca de su distribución.
summary(Filter(is.numeric, f[, -7])) # todas las variables numericas
# Excepto id_clientes
cantidad precioUnitario
Min. :-80995.00 Min. : 0.00
1st Qu.: 2.00 1st Qu.: 1.25
Median : 5.00 Median : 1.95
Mean : 12.06 Mean : 3.46
3rd Qu.: 12.00 3rd Qu.: 3.75
Max. : 80995.00 Max. :38970.00
Salta a la vista que existen algunos valores negativos en la variable 'cantidad', causados por devoluciones,estas devoluciones (valores negativos) deberían cancelarse, en su mayoría,con las ordenes previas, que luego fueron revertidas. Con un gráfico, puede hacerse una comprobación rápida. Hace falta añadir antes la variable 'ingreso'.
f[, `:=` (ingreso = cantidad * precioUnitario)]El paquete xts, facilita la representación de fechas en un gráfico, sin necesidad de recurrir a muchos detalles. Es necesario, convertir las variables a un objeto 'xts', después de cargar el paquete a R.
suppressPackageStartupMessages(library(xts))
f_xts <- f[, .(fecha = paste(substr(fecha_factura, 7, 10),
substr(fecha_factura, 4, 5),
substr(fecha_factura, 1, 2),
sep = "-"),
ingreso = ingreso/1000)]# para expresar el eje de ordenadas en miles
m <- matrix(f_xts[["ingreso"]], nrow = nrow(f), ncol = 1,
dimnames = list(f_xts[["fecha"]], "ingreso"))
matrx_xts <- as.xts(m, dateFormat = "POSIXct")
Ahora se puede graficar el comportamiento de la variable ingreso durante el año.
plot(matrx_xts[matrx_xts > 0],
major.ticks = "months",
minor.ticks = FALSE,
lwd = 3,
ylim = c(-170, 170),
main = "ingresos/devoluciones\n(miles)",
col = 3)
lines(matrx_xts[matrx_xts < 0], col = "firebrick3", lwd = 3)
addLegend("topleft", on = 1,
legend.names = "Ingresos", col = "green", pch = 17,
cex = 1.3)
addLegend("bottomleft", on = 1,
legend.names = "Devoluciones", col = "firebrick3", pch = 17,
cex = 1.3)
Al parecer los valores negativos, tienen una compensación correspondiente en los datos; de modo que al agregarlos tenderan a cancelarse unos con otros (en sus mayoria)
RFM
La variable ingreso, fue creada más arriba, al agregarla por clientes tendríamos la variable monetario; restaría calcular la frecuencia y qué tan recientes son las compras. La palabra recency, la he visto traducida como recencia, realmente no si es una traducción apropiada, sin embargo, para los efectos de este escrito, me pareció conveniente, para designar esa variable.
La fecha de facturación, aparece como tipo 'character', es preciso transformarla en tipo 'date' para poder efectuar operaciones sobre ella.
f[, fecha_factura := readr::parse_datetime(fecha_factura, format = "%d/%m/%Y %H:%M")]
f[, `:=` (recencia = as.Date("2011-12-10") - as.Date(fecha_factura))]
Las variables de RFM, serán un agregado en torno a el mínimo período transcurrido de la última adquisición, la frecuencia en las compras y el valor de estas por cliente.
ds <- f[fecha_factura > "2010-12-09 00:00:00 UTC",
.(recencia = min(recencia),
frecuencia = .N,
monetario = sum(ingreso)), by = id_cliente]
dim(ds)
#[1][1] 4307 4
El conjunto de datos resultante tiene 4307 filas y 4 variables contando la identificación por cliente, además de las correspondientes al RFM. De este conjunto de datos, queda un remanente de 40 individuos, cuyas devoluciones no tienen contrapartida en los datos disponibles.
ds[monetario < 0, .N] # [1] 40El paquete data.table, permite la ordenación rápida en forma decreciente, por la variable 'monetario'
setorder(ds, -monetario)Para hacer más discernible una visualización de estas varibles, puede ser adecuado identificar clientes que aportan mayores ingresos. Si Pareto se cumple, habrá un porcentaje, mas o menos cercano al 20% de clientes, que dan cuenta del 80% de los ingresos y un 80% de clientes que aporta el 20%.
ds[, `:=` (pareto = ifelse(cumsum(monetario) <= .8 * sum(monetario),
"20%-sup", "80%-rest"))]
ds[, pareto := factor(pareto, levels = c("20%-sup", "80%-rest"),
ordered = TRUE)]
En efecto, produce valores similares a los esperados::
ds[,.(totMonetario = sum(monetario), n = .N)] # totMonetario n #1: 8032620 4307 ds[,.(totMonetario = sum(monetario)/8032620 , pct_clientes = .N/4307), by = pareto] # pareto totMonetario pct_clientes #1: 20%-sup 0.7998680 0.2702577 #2: 80%-rest 0.2001321 0.7297423Un 27% de clientes da cuenta del 80% de las ganancias; mientras que el 73% de los clientes aporta un 20% de la valoración monetaria.
Para observar estas variables en un plot la transformación a logaritmos mejora la visualización.
ds[, monetario := ifelse(monetario < 0, 0, monetario)] # hay 40 clientes con valor negativo
ds[, `:=` (recencia.log = log(as.numeric(recencia)),
frecuencia.log = log(frecuencia),
monetario.log = log(monetario))
El código para el plot en 'base':
par(mfrow = c(2, 1), mar = c(5, 4, 3.2, 2))
plot(ds$frecuencia.log, ds$monetario.log, col = ds$pareto,
ylim = c(-30, 20),
bg = "#FFFFFF", ylab = "",
xlab = "", las = 1,
main = "Valor Monetario-\nFrecuencia",
cex.main = .85
)
mtext("(log)", side = 3, cex = .6, line = .2)
plot(ds$recencia.log, ds$monetario.log, col = ds$pareto,
ylim = c(-30, 20),
bg = "#FFFFFF", ylab = "",
xlab = "", las = 1,
main = "Valor Monetario-\nCompras recencias",
cex.main = .85)
mtext("(log)", side = 3, cex = .6, line = .2)
KMEANS
Reatan 40 observaciones, cuyo valor monetario es negativo (devoluciones sin contrapartida. Además hay otras 8 que en transformación logaritmica, tienen valor inferior a cero, debido a lo bajo de los montos. Decidí prescindir de esas observaciones.
round(ds[monetario.log < 0, .N] / nrow(ds) * 100, 1) # [1] 1.2Representan, en conjunto 1.2% de los datos.
Para aislar los efectos, debidos a diferencias em las magnitudes de las tres variables, conviene centrarlos en media y varianza.
ds <- ds[monetario.log > 0, ]
ds[,c("recencia.z", "frecuencia.z", "monetario.z") := lapply(.SD, scale, center = TRUE, scale = TRUE),
.SDcols = c("recencia.log", "frecuencia.log", "monetario.log")]
El algoritmo (kmeans) requiere la escogencia a priori del centros o clusters. Para buscar un posible 'mejor' número de clusters, escribí una función que posteriormente en un loop, servirá para hacer cálculos sucesivos; y finalmente hacer una selección sobre la base de un cierto balance entre el número de clusters y el grado de homogeneidad a lo interno de los clusters.
funkmeans <- function(x) {
output <- kmeans(ds[, 9:11],
centers = x,
algorithm = "Hartigan-Wong",
nstart = 20L)
return(list(n_clusters = x,
tot.withinss = output$tot.withinss,
betweenss = output$betweenss,
totss = output$totss,
rsquared = round(output$betweenss/output$totss, 2)))
}
El funcional Map(), evita la necesidad de escribir un for-loop, cuyo uso en R, frecuentemente se lee, conviene evitar
kms <- Map(function(x) funkmeans(x),
2:10)
do_df <- as.data.frame(do.call(rbind, kms)) # guardar resultados en data.frame
Podría surgir una advertencia, en referencia a la no convergencia del algoritmo, cuando el argumento centers = 8, en ese caso se necesitaría ajustar el número de iteraciones. Sin embargo, no modificaré este argumento debido a que al producir el scree-plot:
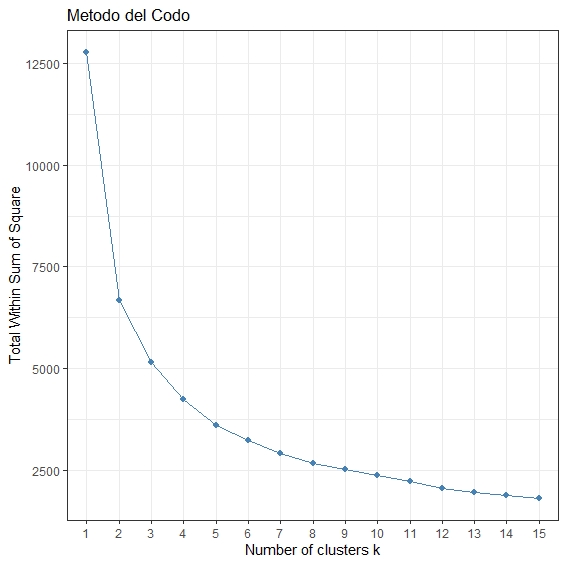
La varianza intra-clusters, disminuye a medida que se incrementa el número de clusters. De hecho, seguramente habrá un punto en el que comenzará subir. Ese punto podría ser el mejor; pero en ese caso, el número de clusters dificultaría toda labor de interpretación. Lo cual dejaría el problema, practicamente en el mismo punto de partida. Es usual buscar trade off. Por ejemplo, en el cuál las disminuciones marginales en la varianza intra-clusters, comienzan a hacerse más pequeñas: el método del codo. Usando ese método, el número apropiado de clusters, estaría en torno a cinco.
El paquete factoextra, ofrece un método equivalente para encontrar el número apropiado de clusters
set.seed(1407)
factoextra::fviz_nbclust(ds[, 9:11], kmeans,
method = "wss",
k.max = 15) + ggplot2::theme_minimal() +
ggplot2::ggtitle("Metodo del Codo") + ggplot2::theme_bw()
Los resultados son bastante parecidos.
Para observar la configuración de los clusters, en torno a una cifra resumen, por ejemplo la mediana. Un procedimiento, análogo al anterior, permite guardar en una lista las medianas, para todos los resultados,en cuanto a cantidad de clusters propuestos.
funclu <- function(x) {
output <- kmeans(ds[, 9:11],
centers = x,
algorithm = "Hartigan-Wong",
nstart = 20L)
tr <- ds[, .(recencia, frecuencia, monetario,
cluster = output$cluster)]
out <- tr[, .(recencia = median(recencia),
frecuencia = median(frecuencia),
monetario = median(monetario),
N =.N),
by = cluster]
return(out)
}
set.seed(1407)
do_clus <- Map(function(x) funclu(x), 2:10)
do_clus <- lapply(do_clus, function(x) setorder(x, cluster))
DT::datatable(do_clus[[4]])
La lista do_clus, contiene agrupaciones de hasta 10 clusters. Sin embargo, aquí solo se muestran los resultados para cinco clusters (medianas) A medida que el número de clusters crece, los grupos comienzan a hacerse indiscernibles. .
El cluster 5, es el de mayor valoración monetaria, mayor frecuencia de compras y sus adquisiciones son de más reciente data; le sigue el cluster dos, sino en cuanto la datacion de sus compras, si en cuanto a la frecuencia y monto de las adquisiciones, serían las mayores, después de las correspondientes al cluster 5. Luego los clusters 1, 3 y 4 corresponden a segmentos medios sus compras tienden a ser más esporádicas y de monetariamente más bajas. El segmento 4 tiene un período de adquisiciones reciente, pero su frecuencia y valor monetario lo asemeja al cluster 3. En fin, una mirada conocedora desde el punto de vista los dueños o encargados de la tienda, podría facilitar una mejor interpretación de estos resultados. Incluso más o menos clusters podrían tener sentido, de acuerdo a la lectura que ellos hagan de resultados como estos.
Por último puede resultar apropiado, observar estos 5 clusters en 3 dimensiones. Con la ayuda de algunos paquetes se puede obtener brevemente una visualización en 3d, incluso una animación.
kf <- kmeans(ds[, 9:11], centers = 5, nstart = 20L)
ds[, cluster := .(factor(kf[["cluster"]], levels = 1:5,
ordered = TRUE))]
El paquete rgl, ofrece una vista en 3 dimensiones de los clusters.
library(rgl)
open3d()
par3d(windowRect = c(100, 100, 612, 612))
plot3d(ds$recencia.log, ds$frecuencia.log, ds$monetario.log,
type = "s", # "s": spheres, "p": points
col = cols,
xlab = "recencia",
ylab = "frequencia",
zlab = "monetario",
box =F,
size = 2)
legend3d("top", legend = paste("cl", 1:5, sep = ":"), horiz = TRUE,
pch = 16, col = c("#FF8C00","#483D8B", "#BEBEBE", "#BDB76B", "#8B1A1A"),
cex = 1, inset = 0.05)
Con el siguiente loop, se crea una carpeta en la cual se guarda una secuencia de imagenes del gráfico en 3d.
angle1 <- 5
angle <- rep(angle1 * pi/180, 360/angle1)
animation_dir <- paste0(getwd(), "/NewRscripts/DATAsets/animation/")
for (i in seq(angle)) {
view3d(userMatrix = rotate3d(par3d("userMatrix"),
angle[i], 0, 0, 1))
rgl.snapshot(filename = paste(paste(animation_dir,
"frame-", sep = ""),
sprintf("%03d", i), ".png", sep = ""))
}
frames <- paste0("~/NewRscripts/DATAsets/animation/",
"frame-",
sprintf("%03d", 1:72), ".png")
Finalmente, el paquete magick, hace el resto
library(magick) m <- magick::image_read(frames) m <- image_animate(m, fps = 2) # fps: número de cuadros por segundo image_write(m, "movie.gif")
Comentarios
Publicar un comentario